由我院姜富伟教授和我院博士生马甜、中财蒂尔堡项目博士生张宏伟合作撰写的论文《高风险低收益?基于大数据和机器学习的动态CAPM模型的解释》被《管理科学学报》正式接收。
针对中国A股市场存在高贝塔低收益的“低风险定价之谜”,本文以中国股票市场系统性风险测度和均衡风险定价为切入点,使用机器学习算法,结合包括74个微观企业特征和8个宏观经济指标在内的共666个宏微观混合大数据预测变量,首次构建了基于大数据和机器学习算法的中国股市系统性风险测度模型,研究发现新定价模型可以缓解并消除传统模型中证券市场线过于“平坦”的现象,解决低风险定价之谜。具体来说,本文首先基于股市月度数据研究了静态CAPM模型对风险补偿收益的解释力,发现国内股票市场长期存在CAPM模型斜率
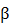 过于平坦和截距
过于平坦和截距
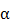 显著大于0的现象。而使用基于机器学习的动态CAPM模型后,定价偏误显著降低(最高降低了96%),在得到有效的定价模型后本文对机器学习中使用的大数据进行了重要度分析并对各个机器学习模型的复杂度进行了研究。同时本文发现中国市场中收益水平变动风险是导致异象产生的主要原因。
显著大于0的现象。而使用基于机器学习的动态CAPM模型后,定价偏误显著降低(最高降低了96%),在得到有效的定价模型后本文对机器学习中使用的大数据进行了重要度分析并对各个机器学习模型的复杂度进行了研究。同时本文发现中国市场中收益水平变动风险是导致异象产生的主要原因。
本文对我国股市动态资本资产定价模型和时变β风险测度做出两大贡献。首先,本文指出我国股市时变贝塔风险不仅受到宏观经济指标的影响还受到经营状况等企业微观特征的影响。比如,假设宏观经济下行会导致企业贝塔风险升高,而那些小盘股、高账面市值比和陷入财务困境的股票的贝塔风险或许会升高的更快。本文在国内率先构建了宏微观混合“大”数据集。具体说,为了尽可能包含更多的有效信息,本文构建的涵盖了包括74个企业微观特征和8个宏观经济指标在内的共666个宏微观混合大数据集。利用宏微观混合大数据进行股票市场系统性风险建模,在数据维度和精度上均较传统模型有了大幅提升,可以进行更有效信息提取和更准确模型预测。
其次,本文使用了机器学习技术开展股市时变贝塔系统性风险建模。随着金融大数据的爆炸式发展,传统经典方法在面对高维的宏微观大数据时候很容易陷入过度拟合和“维度陷阱”,同时在数据挖掘上忽视了金融大数据内在的潜在信息因子、稀疏性和非线性等数据性质。因此,本文使用包括主成分回归、偏最小二乘回归、弹性网络和随机森林等多种机器学习算法替换传统线性回归模型,对宏微观大数据进行降维、变量提取和非线性建模研究,在解决传统模型缺陷的基础上构建更精准的资产系统性风险β。而本文的突出贡献在于将大数据同机器学习算法相结合,将复杂数据进行筛选得到影响系统风险β的重要特征变量,并给出了经济学解释,避免了传统机器学习存在的“黑箱”问题,为后续系统风险的研究提供了探索方向。
